Deploy, Customize and Evolve AI with Inference.
Simplify GenAIOps. UnieAI Studio provides the infrastructure to optimize models using proprietary RL technology.
All Models
0 models availableAccess frontier GenAI models from a single platform
UnieAI Model Zoo features dozens of premium models, enabling developers and enterprises to easily access frontier GenAI models through one unified API.


State-of-the-art models built for real-world applications
We collaborate with industry partners to forge domain-specific SOTA models grounded in real-world use cases. Available as ready-to-call Base Models, our solutions allow you to bypass the complexity of evaluating open-source alternatives and deploy top-tier intelligence immediately.

Optimize AI responses with RL for higher accuracy and lower costs
Leverage our advanced RL optimization algorithm -- UnieMemo (RL for Prompt Tuning) -- to optimize model performance. Achieve higher accuracy at lower cost.

Advanced Agentic Context Engineering algorithms built directly into the API
The UnieAI API features built-in advanced Agentic Context Engineering algorithms to improve accuracy and eliminate hallucinations. It connects to knowledge bases, web pages, MCP Servers, and more to retrieve relevant context in real-time, ensuring AI responses are factual and strictly aligned with your private data.

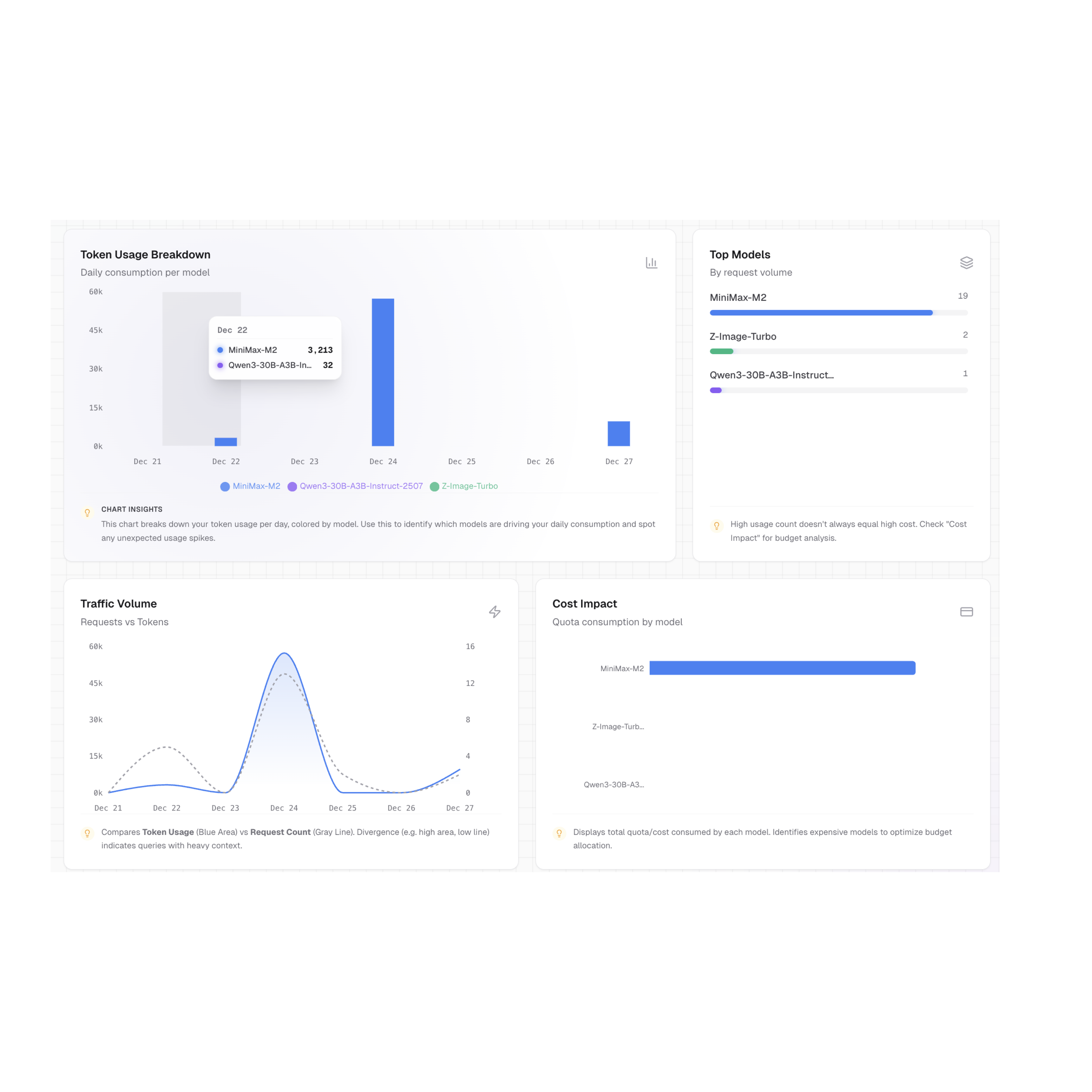
Real-time Token Usage Monitoring and Analytics
Gain full transparency into your AI operations with our comprehensive dashboard. Track token consumption in real-time, analyze usage patterns per model, and manage costs effectively. Our detailed analytics empower you to scale your AI deployment with confidence and control.